| Version 14 (modified by , 17 years ago) (diff) |
|---|
A few notes and thoughts about compressing images to 140 characters, for use on Twitter.
The first I read about this problem was here.
There is now a competition on StackOverflow?.com.
How it works
My goal is to reach a reasonable compromise between the following:
- Fast decompression (a fraction of a second)
- Reasonable compression time (around 1 minute for high quality)
- Achieve decent reconstruction quality
- Work with various message length and character sets
- Do not waste a single bit of information
Here is a rough overview of the encoding process:
- The number of available bits is computed from desired message length and usable charset
- The source image is segmented into as many square cells as the available bits permit
- A fixed number of points (currently 2) is affected to each cell, with initial coordinates and colour values
- The following is repeated until a quality condition is met:
- A point is chosen a random
- An operation is performed at random on this point (moving it inside its cell, changing its colour)
- If the resulting image (see the decoding process below) is closer to the source image, the operation is kept
- The image size and list of points is encoded in UTF-8
And this is the decoding process:
- The image size and points are read from the UTF-8 stream
- For each pixel in the destination image:
- The list of natural neigbours is computed
- The pixel's final colour is set as a weighted average of its natural neighbours' colours
Bit allocation
UTF-8 is restricted to the formal Unicode definition by RFC 3629, meaning that once the 2¹¹ high and low surrogates and the 66 non-characters are removed from the U+0000..U+10FFFF range, the final size of the UTF-8 character set is 1111998. However, a lot of these characters are undefined, not yet allocated or are control characters. As of Unicode 5.1 there are only 100507 graphic characters.
The number of bits that can be expressed in a 140-character message using this charset is:
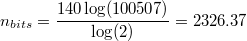
If we restrict ourselves to the 20902 characters available in the CJK Unified Ideographs block, the number of bits becomes:
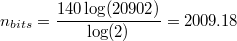
And finally, using the 94 non-spacing, printable ASCII characters:
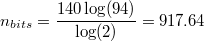
Optimised bitstream
There is a common misconception that values in an information stream should be bit-aligned. This is not the case at all in img2twit: the bitstream can store integer values with non-power of two bounds.
As an illustration, take the example of 16-bit colour coding. There are basically two widespread ways of storing RGB data into a 16-bit word: either using 5 bits per component and wasting the last bit, or using 6 bits for the G value, because the human eye is more sensible to variations of green. The RGB triplet is then computed as (((R) * 64 + G) * 32 + B), and eg. the green value is retrieved as (RGB / 32) % 64. Though 5-6-5 looks rather balanced, that's actually 32 values of red, 64 values of green and 32 values of blue: twice as many values of green... is this really required?
In this case, img2twit's approach would be to use 40 values of each component, where the RGB triplet is computed as (((R) * 40 + G) * 40 + B), and eg. the green value is retrieved as (RGB / 40) % 40. This makes the computations a lot slower (modulo 64 is just a bit shift, while modulo 40 requires dividing the whole bitstream by 40). However, it offers better packing and a lot more control over the data representation. For instance, I found that 2 bits (4 values) per colour component was not enough, but that 3 bits (8 values) was more than required. I went for 6 values (2.58 bits).
One drawback is that this makes the bitstream completely unable to recover from bit corruption. However, for such small streams I don't care at all.
Point selection
I use 16 values for the X and Y position of a point within a cell, and 6 values for each R, G and B component. This uses roughly 15.755 bits. There is a way to reduce this value down to 15.252 bits by accounting for the fact that two points within a cell are interchangeable, but I have not yet found an elegant way to remove the duplicate information without butchering a lot of code.
Algorithm seed
For the algorithm to converge quickly, the initial image needs to be as close as possible to an ideal solution. Of course the method works correctly with an initial random seed, but since the fitting is very slow, it can take 2 to 3 times as long to converge to the same solution.
My current approach is to look at the current cell's brightest and darkest pixels, and to set the two initial points at these locations. There is a lot to be improved in this domain.
Image rendering
The final image is simply an interpolation of the control points stored in the image. I use natural neighbour interpolation because it is reasonably fast (remember that the main algorithm loop computes the changes caused by changes to points, and thus require at least a partial render).
The rendering method is responsible for both the artifacts (mainly the embossed dots) and the nice edges found in some parts of the resulting images.
Preliminary results
Here are the results of img2twit using 140 characters, restricted to U+4e00..U+9fa5 (CJK Unified Ideographs). The 一一一一 characters at the end of some lines indicate wasted bits that the algorithm is unable to use efficiently yet.


輎污涧噊訞巚戴邨姎士踤倭餜洈塉留宒督虞韀澓觀腆趝禄南栥註谎蝲啎狍麃砘焼謩熁迣菝峰嶺綇檂挀黭朿泊攻确碌埬萚鉄毉瘣璚鯱幩冠恈欘肸熈璶礴瘸蚉绋駡碮挺馮譵膀峞黦墮蠅嚓铙觞睡盧孱鳜载襳迠廅榣缹興戰髅垨衦蒺昺醦颥八圪進桊絞螐嗢盉隬岠慷鎃尜淽阨塶沛顭僚計鯬賥占牓吙硘鷸騢挓磪捤鵘坰硖肕萘饼皹侯滗


姲椟筃偡荛璻琛隞夅镬磤湋亹璠熗凋煐攪泲僶壴鋇廷砪臗旝鳑禛渂澣贱涜慘齋芐梡楉迤椻姫閴飙苟稞痡揦麲笉申檫窬偩掛炘忧阙膇样箠愍畄帠掭歜黵歫徯堠傌蕨鱏鷥軠慰糐掭辢猆孏錦戹濸巉魽嚲腫就恩沽厲測沎婲舁铧蠃犱闆醛焊茴鋈叶狝痺矹铓疿镭緄熐魆郗忤櫯嫟韥烥彸漻藉醺夝趼惻炘訶焝汒蝧潚诪躗丌一一一一一一


郚辡帅轻垟比芼瘳僺輪磀蜮箁捆婊滭九輤涇玪曃擾褗眗鯮鴚瘟糱靌軏膒跬泵庠譀奘骰偂穖蠵詟沛駮胅卛唁澥込圊澟褡怍两鋅蠤振殰芝耹漹樆蜬龆绎薄核琣捷椁桡痻擏翵峺侞骯溞淎搼曇壧屳跖忄篵雸皰堫谳物渷厸则陃妔醀垻槥彾澪烃瓾鐬轧錈宓皪瀅榦睿宖陗邱鄎巊晨誫鲛蒹瓬棟层鶾牪耣騝墙麇拫途薱鱤朤慦豹怂傍殐欜一
![]()

坍嗝昫噰碒荓奊镂胆鶊灦翵歓八罡睂釬篾媹蹛赜言齊瓰谕豭璞捘帔穼柞娀癥卢栀儻湐崽洧俅蔿尘犁倴苠鹯焋朓嗸哉姟箊燐蘫矻豣底氲浧喋婏氾藽憺鄐嵔武枣歚雛胠蓸豑逿娳繜婔涙賁醙淸鍮蕙悢龡賚厴惌鎛膟缷概狙峴鋱鮬刬杂蒟驇骧袹璹導练閦饥頖筎梋炻鼑鎄薕粮軝帨雡豄瀴诨霉窐搉裷橌漣濯超瞉秘驔包颾蘱礜鼦挈蓒諹


豪弅淶鑆斳愔耐俬秱戂孤访红艶劃嬌躑擣昗呎腆猎扭僬题猛嬰頽恓劉檭橀韮闼帣赑峈鮦宝鰢斣麙蓑騰騺鹸希關鈯穨唖秴斮圫究傲駛朘铃邂巢沿譓船櫃晒峩泪蝻鵲皲販口谹鎺侒戣耔凉蠛抏槱戛蝂荄勞攞咉闏涪彃沏全偫吒溸乎洸螕慹鳩弭蚕弣寽砰薨埻铥恣噿悏镏雈壭蒬礡靑徠鼛慗泏郄渺婥俦攨賌羢髙壶耔僪爯姉蔮蠬伣豖弫
Getting img2twit
img2twit is currently research material and is not available in any released software. You can however use it, modify it and redistribute it for any purpose, according to the terms of the WTFPL. Note however that it uses third-party libraries such CGAL (which has odd licensing terms) and Imlib2.
If you wish to try img2twit, get the libpipi source code.
If you just want to have a look at the code, get it from the web-based browser.
Attachments (12)
- lena_std_scaled.png (115.7 KB) - added by 17 years ago.
- Mona_Lisa_scaled.jpg (29.4 KB) - added by 17 years ago.
- so-logo.png (9.6 KB) - added by 17 years ago.
- mandrill_scaled.jpg (12.2 KB) - added by 17 years ago.
- Cornell_box_scaled.png (45.6 KB) - added by 17 years ago.
- twitter3.png (71.5 KB) - added by 17 years ago.
- twitter5.png (78.8 KB) - added by 17 years ago.
- minimona.jpg (536 bytes) - added by 17 years ago.
- minimona2.png (15.0 KB) - added by 17 years ago.
- twitter1.png (79.9 KB) - added by 17 years ago.
- twitter2.png (103.5 KB) - added by 17 years ago.
- twitter4.png (20.0 KB) - added by 17 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip