

Warning: this document is still work in progress. Feel free to send comments but do not consider it final material.
So far all dithering methods have relied on the assumption that carefully positioned black and white pixels gave the illusion of greyscales, but we have not stated exactly how the human eye reacted. Also, we do not have an automated way to compare the results of two different algorithms: judging that an algorithm is “better” has mostly been a subjective process so far.
In order to figure out what the human eye really sees, we need a human visual system (HVS) model. Countless models exist, and we are only going to focus on simple ones for now.
One of the simplest models is the gaussian HVS model. It states that the human eye acts like a gaussian convolution filter, slightly blurring pixel neighbourhoods and therefore simulating what the eye sees as distance from the image increases. This model, a simplified luminance spatial frequency response formula, can be expressed using the two-dimensional e -(x²+y²)/2σ² function. The σ parameter sort of introduces the viewing distance into the model.
Here are the results of applying a gaussian HVS to an 8×8 Bayer dithered image, simply by convoluting the image with a gaussian blur filter. This process is also known as inverse halftoning. Different values of σ simulate what the eye sees from different distances. On the left σ = 1, on the right σ = 2:
![]()
![]()
We have already seen that standard error diffusion methods do not go back to pixels that have been set. Direct binary search [4] (DBS) is an iterative method that processes the image a fixed number of times, or until the error can no longer be minimised:
The efficiency and quality of DBS depend on many implementation details, starting with the HVS model it uses to compute the error. Also, the initial image used as iteration zero will give poor results if pattern artifacts are already present. The order in which pixels are processed is important, too. Unfortunately, despite its very high-quality results, DBS is usually a very slow algorithm.
Below is an example of the algorithm results. The HVS uses a 11×11 convolution kernel of the e -sqrt(x²+y²) function. The initial image is randomly thresholded, and pixels are processed in raster order. Iterations 1, 2 and 5 are shown:
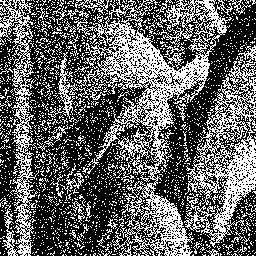
![]()
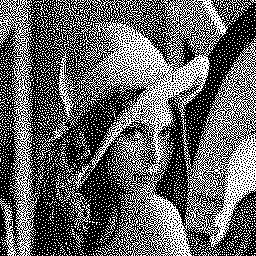
![]()
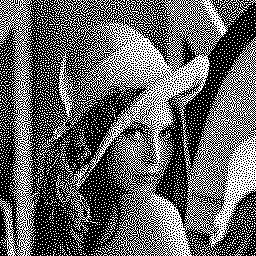
![]()
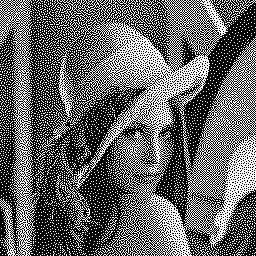
![]()
Other HVS models can be used, giving very high quality results. Below are the results of DBS with the following HVS functions:
The iteration shown is number 5. More iterations would have improved the results even slightly more, but that would have been at the expense of performance:
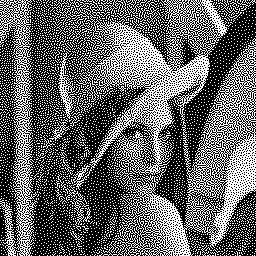
![]()

![]()

![]()

![]()
Using an HVS model, it is possible to classify previously seen algorithms simply by applying the model to both the source and the destination images, and computing their per-pixel mean squared error. This gives a better estimation of the dithering algorithm’s quality than simply computing a local, pixel-bound error.
The following table shows that different HVS models give very different error values depending on the value of σ. Also, in the case of the DBS algorithm, a carefully crafted HVS function such as the last one, which combines two different HVS models, gives low error values at every σ, which means the dithered image is close to the original image at all corresponding viewing distances:
| Chapter 1: Thresholding | Error % σ = 1 | Error % σ = 1.5 | Error % σ = 2 |
|---|---|---|---|
| 0.5 thresholding | 8.60303 | 7.93554 | 7.42669 |
| 0.4 thresholding | 9.78990 | 9.10994 | 8.61878 |
| 0.6 thresholding | 10.77689 | 10.33373 | 10.00462 |
| dynamic thresholding | 10.31568 | 9.60749 | 9.09760 |
| uniform random dithering | 1.57895 | 0.69762 | 0.39713 |
| gaussian random dithering | 2.95590 | 2.34461 | 2.08792 |
| Chapter 2: Halftoning | Error % σ = 1 | Error % σ = 1.5 | Error % σ = 2 |
| 25/50/75% patterns dithering | 0.56642 | 0.46490 | 0.41816 |
| 2×2 Bayer dithering | 0.56694 | 0.46622 | 0.41956 |
| 4×4 Bayer dithering | 0.20538 | 0.08060 | 0.05457 |
| 8×8 Bayer dithering | 0.19691 | 0.06352 | 0.03354 |
| 4×4 cluster dot dithering | 1.20026 | 0.14863 | 0.07100 |
| 8×8 cluster dot dithering | 3.86236 | 0.85236 | 0.14443 |
| 5×3 artistic line dithering | 2.75590 | 0.49420 | 0.11578 |
| perturbated 8×8 Bayer dithering | 0.40550 | 0.16971 | 0.09804 |
| random 3×3 dithering matrix selection | 0.60329 | 0.25055 | 0.16521 |
| “plus” pattern dithering | 0.43061 | 0.33540 | 0.29851 |
| “hex” pattern dithering | 0.26747 | 0.16119 | 0.13068 |
| “doubleplus” pattern dithering | 0.42852 | 0.12232 | 0.08904 |
| “hex2” pattern dithering | 0.35057 | 0.13046 | 0.09533 |
| 4-wise supercell “plus” pattern dithering | 0.21903 | 0.07494 | 0.04423 |
| 3-wise supercell “hex” pattern dithering | 0.21621 | 0.07356 | 0.04193 |
| 4-wise supercell “doubleplus” pattern dithering | 0.40883 | 0.07051 | 0.03609 |
| 6th order dragon curve dithering | 0.20503 | 0.06719 | 0.03539 |
| 3-wise supercell “hex2” pattern dithering | 0.32643 | 0.07861 | 0.04061 |
| 9-wise supercell “hex2” pattern dithering | 0.32336 | 0.07775 | 0.04087 |
| 14×14 void-and-cluster dithering | 0.19726 | 0.06748 | 0.03663 |
| 25×25 void-and-cluster dithering | 0.19248 | 0.06267 | 0.03325 |
| Chapter 3: Error diffusion | Error % σ = 1 | Error % σ = 1.5 | Error % σ = 2 |
| naïve error diffusion | 0.33352 | 0.06372 | 0.01961 |
| Floyd-Steinberg error diffusion | 0.09249 | 0.01847 | 0.00859 |
| serpentine Floyd-Steinberg error diffusion | 0.09891 | 0.01849 | 0.00749 |
| Jarvis, Judice and Ninke dithering | 0.27198 | 0.06257 | 0.03472 |
| Fan dithering | 0.10220 | 0.01728 | 0.00705 |
| 4-cell Shiau-Fan dithering | 0.11618 | 0.01785 | 0.00660 |
| 5-cell Shiau-Fan dithering | 0.11550 | 0.01950 | 0.00708 |
| Stucki dithering | 0.19765 | 0.05373 | 0.03012 |
| Burkes dithering | 0.15831 | 0.04014 | 0.02178 |
| Sierra dithering | 0.23498 | 0.05415 | 0.03011 |
| Sierra 2 dithering | 0.22249 | 0.05121 | 0.02812 |
| Filter Lite | 0.09740 | 0.01605 | 0.00638 |
| Atkinson dithering | 0.47209 | 0.31012 | 0.27339 |
| Riemersma dithering on a Hilbert curve | 0.28224 | 0.06529 | 0.02693 |
| Riemersma dithering on a Hilbert 2 curve | 0.26622 | 0.06003 | 0.02492 |
| spatial Hilbert dithering on a Hilbert curve | 0.27289 | 0.06124 | 0.02184 |
| spatial Hilbert dithering on a Hilbert 2 curve | 0.22821 | 0.05246 | 0.01911 |
| dot diffusion | 0.38301 | 0.08063 | 0.01918 |
| dot diffusion with sharpen = 0.9 | 0.78546 | 0.34941 | 0.23479 |
| dot diffusion with sharpen = 0.9 and zeta = 0.2 | 2.91287 | 2.19398 | 1.99858 |
| serpentine Floyd-Steinberg with sharpen = 0.9 | 0.62615 | 0.30851 | 0.22111 |
| omni-directional error diffusion | 0.23860 | 0.06821 | 0.03498 |
| Ostromoukhov’s variable error diffusion | 0.11203 | 0.01772 | 0.00593 |
| nearest block matching with 2×2 line tiles | 1.92430 | 1.34822 | 1.13685 |
| block error diffusion with 2×2 line tiles | 0.86807 | 0.22411 | 0.08901 |
| block error diffusion with 3×3 artistic tiles | 1.78626 | 0.56957 | 0.23000 |
| block error diffusion with all 2×2 tiles | 0.56466 | 0.15910 | 0.06946 |
| block error diffusion with all 2×2 tiles and weighted intra-block error distribution |
0.37738 | 0.10434 | 0.04643 |
| sub-block error diffusion with all 2×2 tiles | 0.14697 | 0.02605 | 0.00894 |
| sub-block error diffusion with 2×2 line tiles | 0.35759 | 0.06081 | 0.01855 |
| sub-block error diffusion with all 3×3 tiles | 0.32802 | 0.06516 | 0.02165 |
| sub-block error diffusion with 3×3 artistic tiles | 1.03963 | 0.21839 | 0.06678 |
| Chapter 4: Model-based dithering | Error % σ = 1 | Error % σ = 1.5 | Error % σ = 2 |
| DBS with HVS e -sqrt(x²+y²), iteration 1 | 0.25810 | 0.06780 | 0.03489 |
| DBS with HVS e -sqrt(x²+y²), iteration 2 | 0.13762 | 0.03234 | 0.01939 |
| DBS with HVS e -sqrt(x²+y²), iteration 5 | 0.10452 | 0.02745 | 0.01918 |
| DBS with HVS e -(x²+y²)/2, iteration 5 | 0.10344 | 0.03860 | 0.02669 |
| DBS with HVS e -(x²+y²)/4.5, iteration 5 | 0.18034 | 0.00984 | 0.00219 |
| DBS with HVS e -(x²+y²)/8, iteration 5 | 0.37804 | 0.02866 | 0.00295 |
| DBS with HVS 2e -(x²+y²)/1.5 + e -(x²+y²)/8, iteration 5 | 0.09838 | 0.00884 | 0.00263 |